By Alexandre Elias (modified for the sci.lang.japan FAQ)
This document introduces how Japanese text is encoded on computers.
Japanese has three main writing systems: hiragana, katakana and kanji. Roman letters (a, b, c ...), arabic numerals (0, 1, 2 ...) and various punctuation marks (。, !, ?, 「, 」...) (see What are the names of the Japanese non-kana, non-kanji symbols?) are also found in Japanese writing. All of these different writing systems can be found in the same sentence. Here is an example:
UNIX での日本語文字コードを扱うために使用されている従来の
EUC
は次のようなものでした。
This means "The conventional EUC encoding used to handle Japanese
character codes on Unix was as follows."
Each hiragana, katakana, or kanji character is square and of similar size.
Japanese was traditionally written in columns, from top to bottom, with succeeding columns going right to left. See Can Japanese be written right to left? Nowadays, Japanese is often written in rows going from left to right, like English. Apart from word processing and desktop publishing programs, left-to-right writing is almost always used on computer displays.
Hiragana and katakana together are known collectively as the "kana". There are about fifty hiragana and fifty katakana. Each hiragana has a katakana equivalent: they are analogous to small and capital letters. Unlike roman letters, their size does not vary. Hiragana have a smooth curvy appearance, whereas katakana are blocky and jagged. Each kana corresponds to one syllable. Here are a few kana:
| ka | ki | ku | ke | ko | |
| Hiragana | か | き | く | け | こ |
| Katakana | カ | キ | ク | ケ | コ |
The kanji are a complex ideographic writing system from China. See Kanji They remain very similar to Chinese to this day. The kanji are unified with Chinese and Korean in the Unicode character set. There are thousands of kanji in common use in Japan. The quantity of kanji makes Japanese writing difficult both to learn and to encode on computers. Kanji can be recognized by their complex, intricate appearance: for example, 通, 飛, and 治 are common kanji. But a few kanji look simple, such as 人 and 女.
Because the kana can express all possible sounds in Japanese, it is possible to write any Japanese sentence using only one of the two kana writing systems. Thus, the earliest standard Japanese character set for computers (JIS X 0201, described later) supported only katakana, which, although inconvenient, was sufficient.
A character set is a one-to-one mapping between a set of distinct integers and a set of written symbols. For example, define a new character set FOOBAR that maps the alphabet {A, B, C} to the digits 1, 2, and 3, respectively. A character set is an abstract concept that exists only in the mind of the programmer: computers do not directly manipulate character sets.
An encoding is a way characters are stored into 0s and 1s of computer memory. To implement FOOBAR support on a real computer, the most obvious way to encode data would be to represent one character per byte, following the usual way of encoding integers in binary. In this scheme, the string "AABC" would become:
00000001 00000001 00000010 00000011This is how ASCII is normally encoded. But since there are only three distinct characters in FOOBAR, it seems rather wasteful in this case. Alternatively, two bits could be used for each character in the string. This would allow us to cram the entire string "AABC" into one byte:
01011011The encoding has changed, but the character set remains the same. In general, no matter how twisted and convoluted the encoding scheme becomes, conceptually {A,B,C} still maps to {1,2,3}.
In real life, encodings tend to multiply uncontrollably as implementers accommodate the quirks in their systems, but character sets remain few. In the English-speaking world, the only two character sets on the radar are ASCII and EBCDIC. Similarly, there are only two character sets used to write Japanese: the JIS (Japanese Industrial Standard) character set and Unicode. (And the Japanese part of Unicode is actually derived from JIS.)
Unicode is the new, superior standard. Japanese computers have been using JIS for decades, and Unicode has only appeared in the past few years. More and more Japanese text is written in Unicode, but it is still necessary to deal with both JIS and Unicode text.
As needs have evolved, both standards have undergone several revisions. This is mainly a problem with JIS, since its revision process has been somewhat chaotic. In contrast, Unicode follows a policy that each new revision must be a strict super-set of previous ones, so version conflicts rarely cause problems.
There are three JIS encodings (Shift JIS, EUC, ISO-2022-JP) and three Unicode encodings (UTF-8, UTF-16, UTF-32) in widespread use. In a nutshell:
JIS stands for "Japanese Industrial Standard", in Japanese Nihon Kōgyō Kikaku (日本工業規格). JIS is a blanket term used to describe all non-Unicode Japanese character sets and encodings, all of which are based on standards published by the Japanese Standards Association, Nihon Kikaku Kyōkai (日本規格協会) in Japanese.
Unlike Unicode, there is no single JIS character set. A JIS encoding actually involves several standard character sets used in combination:
The "X" in the names of these standards is a code for information technology related standards.
JIS encodings employ various methods to use these overlapping character sets together.
The above four JIS standards are the important ones, but for
reference, here is the meaning of all the JIS X 200 codes:
JIS X 0201 - Roman/katakana (JG)
JIS X 0202 - ISO-2022-JP
JIS X 0203, 0204, 0205, 0206, 0207 - Obsolete/withdrawn standards
JIS X 0208 - Main kanji character set (JH)
JIS X 0209 - How to write JIS X 0211 characters
JIS X 0210 - How to encode numbers
JIS X 0211 - Standard ASCII control codes
JIS X 0212 - Supplemental character set (JJ)
JIS X 0213 - New unified JIS character set
JIS X 0218 - Definition of standard prefixes (JG, JH, JJ, JK, JL)
JIS X 0221 - Unicode (JK for UCS-2, JL for UCS-4)
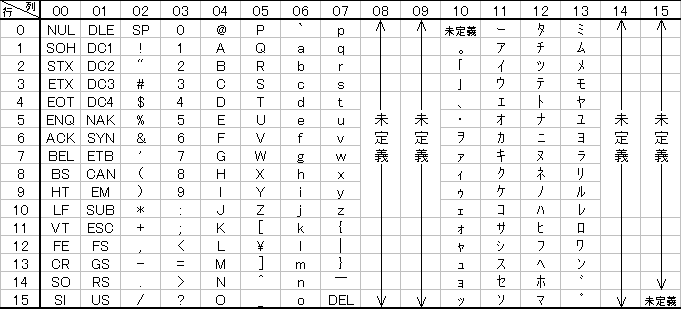
JIS X 0201 is an eight-bit character set which supports only katakana and the ASCII characters. JIS X 0201 hexadecimal character codes can be prefixed with "JG" to distinguish them from other JIS character sets. It was designed in the 1960s (long before the other standards), when computers were not powerful enough to store kanji.
The 7-bit part (i.e. 0x00 to 0x7f) of JIS X 0201 is identical to ASCII, with two exceptions: the backslash character '\' (0x5c) is replaced by a yen symbol, and the tilde character '~' (0x7c) becomes an overline. Thus, displaying ASCII text in a Japanese font will work almost perfectly — except that all backslashes will turn into yens. This problem is so pervasive that it is no longer really a "problem" at all: Japanese people all know and expect to find yen symbols instead of backslashes in such things as DOS/Windows path separators.
This part of this encoding is also known as JIS Roman.
The 8-bit part is divided in this fashion:
0x80 to 0xa0 inclusive: Reserved
0xa1 to 0xdf inclusive: Japanese-style punctuation and half-width katakana
0xe0 to 0xff inclusive: Reserved
The katakana are "half-width", in other words tall and thin, because makes them the same size as roman letters, and thus easy to display on fixed-width terminals. See What is half-width katakana?
JIS X 0208 is the most important standard. When people say "the JIS standard", they mean JIS X 0208. JIS X 0208 hexadecimal character codes can be prefixed with "JH" to distinguish them from other JIS character sets. It has gone through four official versions from the Japanese Standards Association.
Revision history:
| 1978 | The standard was created, as JIS C 6226. This version is also known as "Old-JIS". It is now more or less dead. |
|---|---|
| 1983 | The standard was changed for the 1981 Jōyō kanji list (see What are the Jōyō Kanji?). |
| 1990 | Two kanji were added to the end. |
| 1997 | Six kanji were added to the end. |
The 1983, 1990 and 1997 standards are essentially the same, being close supersets of each other. They are collectively known as "New-JIS", or mostly just "JIS". Thus it is possible to talk about "JIS X 0208" without mentioning the year. The kanji included in these standards are the JIS level one and two kanji. See What are JIS level one and two kanji?
JIS X 0208 is set up as a 2-dimensional, 94x94 grid. The position of a character on this grid is called its "kuten" (区点). The horizontal lines on the grid are:
| Line | Content |
|---|---|
| 01-02 | Punctuation, symbols |
| 03 | ISO 646 (alphanumerics only) |
| 04 | Hiragana |
| 05 | Katakana |
| 06 | Greek |
| 07 | Cyrillic |
| 08 | Line drawing |
| 16-47 | Kanji level 1 (2965, ordered by on'yomi) (see Why do kanji have several different pronunciations?) |
| 48-83 | Kanji level 2 (3390, ordered by Kangxi radical, then stroke) (see What are kanji radicals?) |
| 84 | Miscellaneous kanji (6) |
This 94x94 grid fits between 33 and 126 inclusive, almost completely overlapping the non-control part of ASCII. The hexadecimal JIS code is a 16-bit code resulting from adding 32 to both the ku and the ten, and concatenating the two resulting bytes, the vertical coordinate becoming the high byte. For example, the kanji 私, watashi, "I", has a kuten code of 27-68. The "ku" part is 27, giving a byte value of 27 + 32 = 59, which is 3B in hexadecimal, and the "ten" part is 68, giving a byte value of 68+32 = 100, which is 64 in hexadecimal, thus the hexadecimal JIS code is 3B64.
The kanji in JIS X 0208 are enough for the vast majority of writing, but every so often a rarer kanji is needed (to write names especially). This is why the following standards exist.
JIS X 0212 was introduced in 1990 to accommodate the demand for rare kanji. JIS X 0212 hexadecimal character codes can be prefixed with "JJ" to distinguish them from other JIS character sets. It is meant to be used in the same encoding alongside JIS X 0208. It contains 5801 obscure level 3 kanji. Even educated native Japanese people will not be familiar with most of them.
Like JIS X 0208, it is organized in a 94x94 grid. Here is a description of each horizontal line on the grid:
| Line | Content |
|---|---|
| 02 | More punctuation, symbols |
| 06 | Accented Greek |
| 07 | Non-Russian Cyrillic |
| 09 | Extended Latin |
| 10 | Uppercase accented Latin |
| 11 | Lowercase accented Latin |
| 16-77 | Kanji level 3 (5801, ordered by Kangxi radical, then stroke) |
Because of its overlap with JIS X 0208, encodings have to jump through hoops to use both JIS X 0208 and JIS X 0212 in the same text. Moreover, it leads to confusion. JIS kanji 0x6666 might be JH6666 or JJ6666. The only nice thing is that, though the kanji don't, at least the non-kanji parts of JIS X 0208 and JIS X0212 occupy disjoint code ranges.
JIS X 0213 is the successor to JIS X 0208. It is sometimes called JIS2000 (having been standardized in the year 2000). It is not yet in wide use: for now, it can be ignored. However, for future reference, here is a brief description.
The design of JIS X 0213 is clever. The new characters in JIS X 0213 are mostly kanji and a few miscellaneous other characters. The standard is divided into two parts. Level 3 kanji in JIS X 0213 are said to be in "Plane 1", and Level 4 kanji are said to be in "Plane 2". Both planes are a 94x94 grid.
Here is the trick: Plane 1 kanji occupy the unused codespace in JIS X 0208, whereas Plane 2 kanji occupy the unused codespace in JIS X 0212. To visualize what is happening, imagine printing out the JIS X 0208 grid, the JIS X 0212 grid, the JIS X 0213 plane 1 grid and the JIS X 0213 plane 2 grid on four separate sheets of transparent plastic. Then place the JIS X 0213 plane 1 sheet over the JIS X 0208 sheet without any overlapping characters, and place the JIS X 0213 plane 2 sheet over the JIS X 0212 sheet with no overlap.
To accommodate JIS X 0213, all 3 major JIS encodings have undergone revision. Their new MIME names are EUC-JISX0213, Shift_JISX0213, and ISO-2022-JP-3. Fortunately, because of the clever design of JIS X 0213, the new encodings are only slightly different from their original version.
NEC/IBM defined roughly a thousand new characters for use with CP932 (code page 932), Microsoft's proprietary extension of the Shift JIS encoding. These cause no end of problems, even having duplicates with standard characters. As these characters are tightly bound to CP932, they are described in CP932.
EUC (Extended Unix Code), also known as UJIS, is an encoding which encodes all the characters of JIS X 0201, JIS X 0208 and JIS X 0212. It is compatible with ASCII, but not with JIS X 0201: EUC does not support 1-byte half-width katakana/punctuation (though it does support it in 2 bytes).
Similar to UTF-8, EUC has the property that ASCII characters are left as-is, and every other character has the top bit of each of its bytes set.
Each character set is encoded as follows:
| Charset | Bytes per char | 1st byte | 2nd byte | 3rd byte | Example |
|---|---|---|---|---|---|
| JIS X 0201 | Two | 0x8E | The raw JIS X 0201 byte. | カ (0xB6 in JIS X 0201) ⇒ 8E:B6 | |
| JIS X 0208 | Two | Set the top bits of the JIS X 0208 two-byte code | 河 (32:4F in JIS X 0208) ⇒ B2:CF | ||
| JIS X 0212 | Three | 0x8F | Set the top bits of the JIS X 0212 codes | 傺 (32:30 in JIS X 0212) ⇒ 8F:B2:B0 | |
Note, though, that it may be a bad idea to use characters in JIS X 0212 with EUC, as some software might not recognize them. Because almost all characters in EUC take up only 2 bytes, it is all too easy for careless programmers to build software that will break when it encounters a 3-byte EUC character.
EUC's standard MIME label is "EUC-JP".
JIS X 0213 note: With the advent of JIS X 0213, EUC was extended to support the new characters, and given the MIME label "EUC-JISX0213" (not yet standard). The extension is simple. Recall that JIS X 0213 plane 1 fits into the unused codespace of JIS X 0208, and JIS X 0213 plane 2 fits into the unused codespace of JIS X 0212. EUC-JISX0213 is identical to ordinary EUC-JP, except that it allows encoding JIS X 0213 plane 1 characters just as JIS X 0208 characters are encoded (in 2 bytes), and JIS X 0213 plane 2 characters just like JIS X 0212 characters (in 3 bytes).
Shift JIS is an encoding of the JIS standard which was the standard encoding for Japanese on Microsoft and Apple computers before the advent of Unicode. The selling point of Shift JIS (a.k.a. SJIS) is that, unlike EUC, it is backwards-compatible with not only ASCII, but also JIS X 0201, so Shift JIS can be used to encode both JIS X 0201 and JIS X 0208 (but not JIS X 0212). One-byte half-width katakana/punctuation is valid Shift JIS. Unfortunately, this compatibility means that Shift JIS is the messiest encoding of all.
The first byte of a Japanese character in Shift JIS always has the top bit set and, to permit its use mingled with JIS X 0201 characters, avoids the high JIS X 0201 range of 0xA0 to 0xDF. The second byte's top bit is not necessarily set. It can go all the way from 0x40 to 0xFC (overlapping with ASCII).
The algorithm to convert JIS codes into Shift JIS is complicated, and can't be explained in a nutshell. It involves dividing things by 2 and adding arbitrary magic numbers. See Shift JIS conversions for a precise description.
Shift JIS's standard MIME label is "Shift_JIS".
CP932 (code page 932) is an extension of Shift JIS from Microsoft. It adds the NEC/IBM extended characters. This extension is:
NEC special characters (83 characters in SJIS row 13),Apple also has its own proprietary extension, which is very similar to CP932.
NEC-selected IBM extended characters (374 characters in SJIS rows 89..92),
and IBM extended characters (388 characters in SJIS rows 115..119).
The most widely supported encoding for e-mail is the 7-bit ISO-2022-JP standard, which has been used for Japanese e-mail since the beginning. This encoding is almost certain to be understood by a Japanese recipient. It has also been standardized by the JSA under the name "JIS X 0202".
ISO-2022-JP is essentially a mix of plain ASCII and raw, 7-bit JIS. Like all JIS encodings, 16-bit characters are encoded in big-endian byte order. To distinguish between conflicting character sets, escape codes are used.
There are 3 revisions of ISO-2022-JP. Their MIME labels are "ISO-2022-JP", "ISO-2022-JP-1", and "ISO-2022-JP-2".
ISO-2022-JP - Supports ASCII and JIS X 0208.
ISO-2022-JP-1 - Also supports JIS X 0212.
ISO-2022-JP-2 - Also supports other languages like Chinese and
Greek.
The original ISO-2022-JP will be good enough most of the time. For maximum compatibility, prefer it to the others.
Here are the relevant escape sequences:
| ISO reg# | Character set | ESC sequence | Standard? |
|---|---|---|---|
| 6 | ASCII | ESC ( B | ISO-2022-JP |
| 42 | JIS X 0208-1978 | ESC $ @ | ISO-2022-JP |
| 87 | JIS X 0208-1983 | ESC $ B | ISO-2022-JP |
| none | JIS X 0201 katakana | ESC ( I | Nonstandard |
| 14 | JIS X 0201-Roman | ESC ( J | ISO-2022-JP |
| 159 | JIS X 0212-1990 | ESC $ ( D | ISO-2022-JP-1 |
The text begins in ASCII by default, and it must be switched back to ASCII at the end. It is also recommended for newlines to always be encoded in ASCII. If this is e-mail, the escape codes must be used in the Subject: or From: lines if they contain Japanese, again switching back to ASCII when done.
ESC ( B should be preferred over ESC ( J. The latter is a legacy code whose use is discouraged today. Also, avoid ESC ( I unless half-width katakana are wanted.
By adding escape codes by hand, it is possible to easily send ISO-2022-JP encoded e-mail with any e-mail client, even if it has no support at all for Japanese.
ISO-2022-JP-2 has a variety of other escape codes, having been extended to support random other languages. See RFC1554 for details.
There is a new encoding for JIS X 0213, known by its nonstandard MIME name "ISO-2022-JP-3". It is identical to the original ISO-2022-JP, with the following additional codes.
| ISO reg# | Character set | ESC sequence | Standard? |
|---|---|---|---|
| none | JIS X 0213 plane 1 | ESC $ ( O | ISO-2022-JP-3 |
| none | JIS X 0213 plane 2 | ESC $ ( P | ISO-2022-JP-3 |
Unicode is a character set begun circa 1990. It intends to assign a unique code to every character in every living writing system. Unicode, the character set, is sometimes called UCS (Universal Character Set). Encodings of Unicode are called UTF-something. Pedants make the distinction but both these terms are interchangeable in casual speech.
Many people, when they first hear about Unicode, assume that Unicode encoding is as simple and clean as ASCII, except that each character code maps to 2 bytes instead of just 1. This is wrong. Unicode encodings are much more complicated than this. Making it as simple as ASCII was the naive idea when Unicode was first conceived, but then reality caught up with the standard. There are now no less than 3 popular encodings for Unicode.
Unlike JIS, UCS is not organized in a grid. It is a flat, one-dimensional sequence, with character codes ranging from 0 to 0x10FFFF. A code in this range can almost, but not quite, fit into 20 bits of storage. Each writing system has its own range of codes.
The creators of Unicode thought when they started that 16 bits would be enough to contain all useful writing systems, but they were wrong. The latest Unicode standard goes up to (a little more than) 20 bits, and a kludge was designed to the new high-plane characters in what was previously 16-bit only text (UTF-16, described below). Unicode is now separated into 17 planes, from Plane 0 to Plane 16, the plane number coming from the value of the top 4 bits.
| Plane | Content |
|---|---|
| 0 | Basic Multilingual Plane (BMP) |
| 1 | Obscure character sets like ancient Egyptian |
| 2 | Obscure kanji |
| 3-13 | Unused |
| 14 | Meta-characters |
| 15-16 | Private-use |
Here are the character ranges of interest to us:
| Range | Content |
|---|---|
| 0x0020-0x007F | ASCII |
| 0x3000-0x303F | Japanese-style punctuation |
| 0x3040-0x309F | Hiragana |
| 0x30A0-0x30FF | Katakana |
| 0xFF00-0xFFEF | Full-width roman characters and half-width katakana |
| 0x4E00-0x9FAF | CJK unified ideographs - Common and uncommon kanji |
| 0x3400-0x4DBF | CJK unified ideographs Extension A - Rare kanji |
| 0x20000-0x2A6DF | CJK unified ideographs Extension B - Very rare kanji |
Unlike all the JIS-based standards, which enforce big-endian encoding, Unicode also panders to the little-endian people. Although endianness problems don't appear in UTF-8, which is 8-bit based, they do in UTF-16 and UTF-32, both of which can be either big-endian or little-endian.
Endianness, or byte order, means the order of the bytes when a 16-bit or higher integer is changed into a series of 8-bit bytes. There are two commonly used orders:
Big-endian:
0x1234 -> 0x12, 0x34
0x12345678 -> 0x12, 0x34, 0x56, 0x78
Little-endian:
0x1234 -> 0x34, 0x12
0x12345678 -> 0x78, 0x56, 0x34, 0x12
Thus, both UTF-16 and UTF-32 have 3 MIME labels: "UTF-16", "UTF-16BE", "UTF-16LE", and "UTF-32", "UTF-32BE", "UTF-32LE". "BE" and "LE" stand for big-endian and little-endian, respectively.
When one of the qualified MIME labels is used (and this is preferable), there is no ambiguity, and that is the end of the discussion. But when the ambiguous "UTF-16" and "UTF-32" labels are used (or when the Unicode is found in a file with no external meta-data), the byte order can be either. How can they be told apart?
The answer is the BOM (Byte Order Mark), a two-byte (in UTF-16) or four-byte (in UTF-32) code which can optionally be put at the beginning of a serialization (i.e. file) to specify its endianness. The BOM is considered meta-data, and not part of the actual Unicode text.
The BOM has 4 different forms:
| BOM | Meaning |
|---|---|
| 0xFE, 0xFF | Big-endian UTF-16 |
| 0xFF, 0xFE | Little-endian UTF-16 |
| 0x00, 0x00, 0xFE, 0xFF | Big-endian UTF-32 |
| 0xFF, 0xFE, 0x00, 0x00 | Little-endian UTF-32 |
The code U+FEFF (what the BOM would be if it was a real Unicode character instead of meta-data) is the ZERO WIDTH NO-BREAK SPACE. Not by coincidence, this is an invisible character which does absolutely nothing, so that putting a BOM outside the first character of a file by mistake (for example, by naively concatenating two Unicode files together) will generally have no serious consequences. The code 0xFEFF is always interpreted as a BOM in the first position of the file, and always interpreted as a ZERO WIDTH NO-BREAK SPACE anywhere else.
If the file has no BOM, it is necessary to ask the user or use some other heuristic.
UTF-8 has the following properties:
The encoding is as follows. Take the UCS code in big-endian order and map its bits to the 'x'es in the following table:
U-00000000 - U-0000007F: 0xxxxxxxIt is an error to use more bytes than the minimum. The reason for this rule is that each character should have only one representation.
U-00000080 - U-000007FF: 110xxxxx 10xxxxxx
U-00000800 - U-0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
U-00010000 - U-001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
UTF-8 has no endianness problems. UTF-8 uses "UTF-8" as standard MIME label.
UTF-16 (a.k.a. UCS-2) is the "obvious" encoding of Unicode. Each character code of each Plane 0 character is directly translated to a 16-bit integer.
Before the addition of the new planes, this was the whole story, but now to access them, the reserved codespace of Unicode found between 0xD800 and 0xDFFF inclusively is used. There are no characters in this range. There are eleven bits of free codespace available here.
If plane 0 is omitted, any Unicode character in the higher planes can be expressed in 20 bits. Thus any higher-plane character can be expressed using two 16-bit codes between 0xD800 and 0xDFFF, of which the 10 lowest bits are used in each to encode half the character — always in big-endian order (the high 10 bits are in the first code), regardless of the endianness of the file itself.
The Unicode character number is not encoded directly in these 2 sets of 10 bits: first subtract 0x10000. So Plane 0 cannot be used with this scheme, but Plane 16 becomes available.
The unused 11th bit (0x0400) is used to increase the robustness of UTF-16 text. In the first 16-bit code, the 11th bit is always 0, and in the second 16-bit code, it is always 1. That way, if a file is truncated in the middle of a higher-plane character, a program can tell that it is reading the second half, and not corrupt the character after it.
UTF-16 is affected by endianness issues. See Endianness and the BOM for details.
UTF-16 was adopted by Microsoft for use in their APIs.
UTF-16 has three possible MIME labels. They are "UTF-16BE" for big-endian byte order, "UTF-16LE" for little-endian, and just "UTF-16" for ambiguous (not recommended).
See RFC2781 for an official standard.
UTF-32 (a.k.a. UCS-4) is the simplest of all the Unicode encodings, but also the least efficient. In UTF-32, every character is a direct translation of its Unicode character code to a 32-bit integer. The only tricky part is the endianness issues (see Endianness and the BOM).
UTF-32 is not widely used for interchange because it is very wasteful of space. UTF-16 always outperforms or matches the space performance of UTF-32, usually by a factor of 2. UTF-8 can outperform it by a factor of 4. In any given UTF-32 file, most high bits will be all zeroes, because the vast majority of Unicode characters (including kanji) are in Plane 0, the one that can be encoded with only 16 bits. However, its simplicity makes it very appropriate for internal representation inside programs, which is the main justification for its existence.
UTF-32 has three possible MIME labels. They are "UTF-32BE" for big-endian byte order, "UTF-32LE" for little-endian, and just "UTF-32" for ambiguous (not recommended).
See the Unicode Standard Annex #19 for the official standard.
Punycode is a method whereby Unicode characters can be encoded for use in domain names containing non-ASCII characters. See RFC3492.
These encodings never really caught on.
UTF-7's major property and reason for existence is that it is 7-bit, and thus adequate for e-mail. But because MIME Content-Transfer-Encodings are good enough to use 8-bit encodings in e-mail, this never caught on.
UTF-7, like its JIS sibling ISO-2022-JP, has the property that most ASCII text can be plunked right into it without modification, and an escape character is used to indicate the beginning of "real" Unicode. But instead of using the ESC control code to do this, UTF-7 simply uses the + character. The text following the + is big-endian UTF-16 encoded in a close variant of Base64.
(In a nutshell, Base64 encodes 24 bits into 4 bytes, spreading it out to 6 bits per byte. Each of these bytes is mapped into the following alphabet:
Value Encoding Value Encoding Value Encoding Value Encoding
0 A 17 R 34 i 51 z
1 B 18 S 35 j 52 0
2 C 19 T 36 k 53 1
3 D 20 U 37 l 54 2
4 E 21 V 38 m 55 3
4 F 22 W 39 n 56 4
6 G 23 X 40 o 57 5
7 H 24 Y 41 p 58 6
8 I 25 Z 42 q 59 7
9 J 26 a 43 r 60 8
10 K 27 b 44 s 61 9
11 L 28 c 45 t 62 +
12 M 29 d 46 u 63 /
13 N 30 e 47 v
14 O 31 f 48 w (pad) =
15 P 32 g 49 x
16 Q 33 h 50 y
UTF-7's variant is different only insofar as the pad character '=' is not used.)
When the UTF-16 is finished, the - character acts as terminator. Any character not in the Base64 list will also work as terminator, but only - is swallowed. Therefore, UTF-7 encoded Japanese text will look something like +6shGa5Hp-, or just +6shGa5Hp. An example given in the standard is that the Unicode sequence "Hi Mom -<WHITE SMILING FACE>-!" becomes "Hi Mom -+Jjo--!".
As this encoding is not widely supported and won't ever be, it should not be used in outgoing mail.
UTF-7 uses "UTF-7" as standard MIME label.
See RFC2152 for the official standard.
Another failed encoding scheme whose only strong point is efficiency. SCSU is actually more of a compression scheme than an encoding. The gist of it is that it switches into small 128-character "windows" for the duration of a string, within which characters are encoded only by their offset to the beginning of the window rather than their entire code. This method is worthless for encoding kanji, which are spread out all over the character set. SCSU didn't catch on because more efficient alternatives such as using gzip already existed.
"UTF-1" and "UTF-7,5" may crop up. UTF-1 is an inferior encoding proposed in the early days of Unicode but never much used, now completely superseded by UTF-8. "UTF-7,5" is a variant of UTF-8, proposed long after UTF-8 had already become standard. It offers a few small advantages over UTF-8, but not enough to merit switching over to it. Neither of these will ever be seen in the wild.
The list of Japanese characters in Unicode was ripped straight from JIS, so JIS can be converted into Unicode without many problems. But don't expect perfectly sensible conversions. CP932, Microsoft's proprietary extension of Shift JIS, causes the most trouble. It has duplicates and bad mapping tables that don't do proper round-tripping. If something is converted from Unicode to CP932 and back, the end result is something different from what was started with.
When using any conversion software on Microsoft Windows, be sure to specify CP932 for the encoding, rather than "Shift_JIS". The kanji and kana parts of the text will be the same, but symbols, such as circled numbers like ①, have different values in Shift JIS and CP932.
One of the best conversion tools is the iconv program, part of the libiconv library, distributed freely by GNU at gnu.org under the LGPL. It supports all the important encodings described in this document, even ones as obscure as UTF-7 and the new JIS X 0213 encodings. It can convert from any encoding to any other encoding. It is available as a command-line tool for Unix or as a C library for both Windows and Unixes. For example, to convert kanjidic from EUC into UTF-8:
iconv -f EUC-JP -t UTF-8 < kanjidic > kanjidic_utf8
The Perl programming language supports most encodings via its Encode module. For example, to convert kanjidic from EUC into UTF-8:
perl -CO -MEncode -pe '$_=decode("euc-jp",$_)' < kanjidic > kanjidic_utf8
On Windows, consider also nkf, the "Network kanji filter". It supports EUC, Shift JIS, ISO-2022-JP, and Unicode. To convert kanjidic from EUC into UTF-8:
nkf -E -w8 < kanjidic > kanjidic_utf8It also has a
--guess option where it tries to guess the
encoding of the input.
Japanese web pages are mainly encoded in Shift JIS, EUC or UTF-8. In the past, Shift JIS was the most popular. EUC is found on some sites. Unicode is gradually gaining in popularity. In principle it would be possible to see ISO-2022-JP on web pages, since Internet Explorer supports it, but it is rare.
The MIME label for the encoding is normally specified by the web server inside the HTTP headers. A typical HTTP header's content type looks like
Content-Type: text/html; charset=UTF-8See RFC2616 for full details. For those who don't have access to their web server configuration, the second-best is to specify it with a META http-equiv tag in the HTML head section. This META tag tells the web server to alter what the HTTP header says. It should look like this:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
In fact, it can't hurt to use such a META tag in all Japanese HTML even if the web server is configured to send UTF-8. That will make it easier to switch to another web server, and someone looking at the source will immediately know which encoding is being used, without needing to resort to the rules of thumb in this document.
In addition to the above encodings, HTML allows one to enter Unicode characters by number, using only plain ASCII: for example 字 (including the semicolon) for 字, the character with the hex code 5B57. Or a decimal: 字 These are known as HTML entities. This is the most reliable method and nice for a few Japanese characters in an otherwise English document, but it can be painful to type.
To automatically convert all non-ASCII characters in a document into HTML entities with Perl,
perl -C7 -pe 's/([^\x00-\x7f])/"&#".ord($1).";"/ge;' < in.html > out.htmlfor decimal entities, or
perl -C7 -pe 's/([^\x00-\x7f])/sprintf "&#X%X;", ord $1/ge;'for hexadecimal entities. (This assumes that the input file,
in.html, is UTF-8 encoded.)
To reverse this process,
perl -C7 -pe 's/&#(\d+);/chr $1/ge;' < in.html > out.htmlfor decimal entities like 字, or
perl -C7 -pe 's/&#x([0-9a-f]+);/chr hex $1/gei;' < in.html > out.htmlin the case of hexadecimal entities like 字.
ISO-2022-JP uses only 7 bits and was designed specially for e-mail.
E-mail presents special difficulties, because (apparently) some archaic e-mail relays support only transfers of 7-bit data. If a message contains a byte where the 8th bit is set, it could potentially be corrupted or rejected. Since most of the above methods exploit the 8th bit of each byte, it might not work to naively put Japanese text encoded using one of them directly in an email.
However, this restriction can be circumvented. Email already provides means of getting around the 7-bit problem, for example for binary attachments. The MIME standard for e-mail headers provides, in addition to a means of specifying the text encoding, a "Content-Transfer-Encoding", a standard means of re-encoding text to avoid using the 8th bit. For example, to send a Shift JIS encoded e-mail, specify this in the header:
Content-Type: text/plain; charset=Shift_JIS Content-Transfer-Encoding: base64
The text of the mail would first be encoded in Shift JIS, and then this encoded text would in turn be encoded in Base64 (see section 3.3.1 on UTF-7 for an explanation of Base64). This method could potentially be used to send mail using any of the codings described above. A detailed discussion of MIME content transfer encodings is outside of the scope of this document; see RFC1521 for the MIME standard.
So, if someone doesn't support ISO-2022-JP, try using this method alongside Shift JIS for e-mail. This is a good bet for Windows and Mac users, since Shift JIS is the standard encoding of those systems.
Email headers in Japanese email with Japanese text are usually encoded in a form something like
=?iso-2022-jp?B?GyRCRnxLXDhs?=This is a mail header encoding described in full in RFC2047. Its parts are as follows:
=?<charset>?<encoding>?<data>?=
<charset> indicates the character set, such as
ISO-2022-JP. <encoding> may be
either B for base 64 encoding, or Q for an
encoding in which, for example, the format =20 is used to
escape the character with hexadecimal value 20 (the space
character). In Japanese emails, B for base 64 encoding is
usually used. <data> is then the base 64 encoded
data in the specified character set.
Please see this regarding copyright permissions for this content.
| 規格名称 Spec Name |
発行年 Year published |
内容 Contents |
面区点 Plane-Row-Cell |
文字種数 No. of chars |
ISO-IR | Final Byte | 備考 Comment |
| JIS X 0201 (JIS C 6220) |
1969, 1976, 1997 | ローマ字 Roman = ISO/IEC 646:1991 |
1 to 94 | 94 | 14 | 94 4/10 |
ASCII based. Replaced backslash and tilde with Yen-sign and overline. |
| カタカナ Katakana = ISO/IEC 646:1991 |
1 to 63 | 63 | 13 | 94 4/9 |
Code points 64 to 94 are reserved. | ||
| JIS X 0202 (JIS C 6228) |
1975, 1984, 1991, 1998 | Encoding System = ISO/IEC 2022:1994 |
— | — | — | — | |
| JIS X 0208 (JIS C 6226) |
1978, 1983, 1990, 1997 | 漢字(第一水準) Kanji (JIS level 1) |
1-1-1 to 1-47-94 | Kanji: 2965 Other: 524 |
42,87 | M 4/2 |
五十音順 (Sorted by pronunciation) Included Hiragana, Katakana, Latin, Greek, Cyrillic, Box-line and Symbols. |
| 漢字(第二水準) Kanji (JIS level 2) |
1-48-1 to 1-94-94 | Kanji: 3390 | 42,87 | M 4/2 |
部首順 (Sorted by radical) Some old PC were not supported. | ||
| JIS X 0211 (JIS C 6323) |
1986, 1991, 1994 | C0 = ISO/IEC 6429:1992 |
C0 | — | 1 | C0 4/0 |
|
| C1 = ISO/IEC 6429:1992 |
C1 | — | 77 | C1 4/3 |
|||
| JIS X 0212 | 1990 | 漢字(補助) Kanji (Supplementary) |
2-1-1 to 2-94-94 | Kanji: 5801 Other: 266 |
159 | M 4/4 |
部首順 (Sorted by radical) Included ext.Latin, ext.Greek, ext.Cyrillic and Symbols. |
| JIS X 0213 | 2000 | 漢字(第三水準) Kanji (Level 3) |
1-1-1 to 1-94-94 (*1) |
Kanji: 1249 Other: 659 |
228 | M 4/15 |
部首順 (Sorted by radical) Included ext.Latin, IPA, Katakana(for Ainu) and Symbols. |
| 漢字(第四水準) Kanji (Level 4) |
2-1-1 to 2-94-94 (*2) |
Kanji: 2436 | 229 | M 5/0 |
部首順 (Sorted by radical) 補助漢字とは混在使用しない(Does not use to mix with Supp.Kanji.) | ||
| JIS X 0221 | 1995 | = ISO/IEC 10646-1:1993 | U+0000 to U+FFFD | Kanji: 20902 Other: ? |
162? | w/oSR 4/0? |
部首順 (Sorted by radical in Unified Han Ideograph Area) |
| 名称 Scheme Name |
JIS X 0201 ローマ字 Roman |
ANSI X 3.4 ASCII |
JIS X 0201 カタカナ Katakana |
JIS X 0208 漢字(第一水準) Kanji (Level 1) |
JIS X 0208 漢字(第二水準) Kanji (Level 2) |
JIS X 0212 漢字(補助) Kanji (Supp.) |
JIS X 0213 漢字(第三水準) Kanji (Level 3) |
JIS X 0213 漢字(第四水準) Kanji (Level 4) |
| ISO-2022-JP | ESC ( J 0x21-0x7E |
ESC ( B 0x21-0x7E |
ESC ( I 0x21-0x5F (*3) |
ESC $ B 0x2121-0x4F7E |
ESC $ B 0x5021-0x7E7E |
— | — | — |
| ISO-2022-JP-1 | ESC ( J 0x21-0x7E |
ESC ( B 0x21-0x7E |
ESC ( I 0x21-0x5F (*3) |
ESC $ B 0x2121-0x4F7E |
ESC $ B 0x5021-0x7E7E |
ESC $ ( D 0x2121-0x7E7E |
— | — |
| ISO-2022-JP-2 (*4) |
ESC ( J 0x21-0x7E |
ESC ( B 0x21-0x7E |
ESC ( I 0x21-0x5F (*3) |
ESC $ B 0x2121-0x4F7E |
ESC $ B 0x5021-0x7E7E |
ESC $ ( D 0x2121-0x7E7E |
— | — |
| ISO-2022-JP-3 (*6) |
ESC ( J 0x21-0x7E |
ESC ( B 0x21-0x7E |
ESC ( I 0x21-0x5F (*3) |
ESC $ B 0x2121-0x4F7E |
ESC $ B 0x5021-0x7E7E |
— | ESC $ ( O 0x2121-0x7E7E (*1,*5) |
ESC $ ( P 0x2121-0x7E7E (*2) |
| Shift JIS (*7) |
GL: 0x21-0x7E |
— | GR: 0xA1-0xDF |
0x8140-0x989E (*8) |
0x989F-0x9FFC 0xE040-0xEFFC (*8) |
— | — | — |
| Shift_JISX0213 (*7) |
GL: 0x21-0x7E |
— | GR: 0xA1-0xDF |
0x8140-0x989E (*8) |
0x989F-0x9FFC 0xE040-0xEFFC (*8) |
— | 0x8140-0x9FFC 0xE040-0xEFFC (*1,*8) |
0xF040-0xFCFC (*8,*9) |
| EUC-JP | — | GL: 0x21-0x7E |
SS2: 0x8EA1-0x8EDF |
GR: 0xA1A1-0xCFFE |
GR: 0xD0A1-0xFEFE |
SS3: 0x8FA1A1-0x8FFEFE |
— | — |
| EUC-JISX0213 | — | GL: 0x21-0x7E |
SS2: 0x8EA1-0x8EDF |
GR: 0xA1A1-0xCFFE |
GR: 0xD0A1-0xFEFE |
— | GR: 0xA1A1-0xFEFE (*1) |
SS3: 0x8FA1A1-0x8FFEFE (*2) |
This is included here for reference. Note, however, that it is better not to use the algorithmic method given here for actual conversions, but a table-based lookup, due to incompatibilities introduced in CP932.
| Shift_JIS Shift_JISX0213 |
JIS X 0208 JIS X 0213 |
How to calculate a Shift_JIS or Shift_JISX0213 code from a Plane-Row-Cell of JIS X 0208 or 0213. | |
| 0x8140-0x817E 0x8180-0x819E |
1-1-1 to 94 |
Hi = (0x101 + Row) / 2; |
if (Row & 1) {
if (Cell < 64) {
Lo = 0x3F + Cell;
} else {
Lo = 0x40 + Cell;
}
} else {
Lo = 0x9E + Cell;
}
|
| 0x819F-0x81FC | 1-2-1 to 94 | ||
| 0x8240-0x827E 0x8280-0x829E |
1-3-1 to 94 | ||
| ... | ... | ||
| 0x9F40-0x9F7E 0x9F80-0x9F9E |
1-61-1 to 94 | ||
| 0x9F9F-0x9FFC | 1-62-1 to 94 | ||
| 0xE040-0xE07E 0xE080-0xE09E |
1-63-1 to 94 |
Hi = (0x181 + Row) / 2; | |
| 0xE09F-0xE0FC | 1-64-1 to 94 | ||
| ... | ... | ||
| 0xEF40-0xEF7E 0xEF80-0xEF9E |
1-93-1 to 94 | ||
| 0xEF9F-0xEFFC | 1-94-1 to 94 | ||
| 0xF040-0xF07E 0xF080-0xF09E |
2-1-1 to 94 |
if (Row < 8) {
Hi = (0x1DF + Row) / 2;
} else {
Hi = (0x1D9 + Row) / 2;
}
| |
| 0xF09F-0xF0FC | 2-8-1 to 94 | ||
| 0xF140-0xF17E 0xF180-0xF19E |
2-3-1 to 94 | ||
| 0xF19F-0xF1FC | 2-4-1 to 94 | ||
| 0xF240-0xF27E 0xF280-0xF29E |
2-5-1 to 94 | ||
| 0xF29F-0xF2FC | 2-12-1 to 94 | ||
| 0xF340-0xF37E 0xF380-0xF39E |
2-13-1 to 94 | ||
| 0xF39F-0xF3FC | 2-14-1 to 94 | ||
| 0xF440-0xF47E 0xF480-0xF49E |
2-15-1 to 94 | ||
| 0xF49F-0xF4FC | 2-78-1 to 94 |
Hi = (0x19B + Row) / 2; | |
| 0xF540-0xF57E 0xF580-0xF59E |
2-79-1 to 94 | ||
| ... | ... | ||
| 0xFC40-0xFC7E 0xFC80-0xFC9E |
2-93-1 to 94 | ||
| 0xFC9F-0xFCFC | 2-94-1 to 94 | ||
Above tables copyright (C) 2001 イオ (smile4me@ps.ksky.ne.jp), All Rights Reserved.
Please see this regarding copyright permissions for this content.
Short introduction to encodings of Japanese, with editorializing. A little dated.
Dates back to 1996. Thorough-going review of coding standards at that time.
Dates back to 1996. Quickie page on the three Japanese encodings, iso-2022-jp, EUC, and Shift JIS. Includes useful diagrams.
Detailed specifics for programmers and Unix users.
Information on Unicode for the world wide web and software. Very big site, but its lists of software are now outdated.
Copyright © 1994-2026 Ben Bullock
If you have questions, corrections, or comments, please contact Ben Bullock or use the discussion forum / News / Privacy policy

|

|
|

|

|
| Book reviews |
Convert Japanese numbers |
Handwritten kanji recognition |
Stroke order diagrams |
Convert Japanese units |